공유자원 접근
#Kotlin #Kotlin_Coroutine #Thread #Kotlin_Coroutine_Actor #Mutex #Semaphore #Volatile
1. 공유자원
1-1. 공유자원이 뭐지?
공유자원이란 여러 프로세스나 스레드가 공통적으로 접근할 수 있는 자원을 말한다. JVM으로 생각해보면 Method Area와 Heap Area에 존재하는 인스턴스나 변수가 있을 것이다.
1-2. 공유자원은 우리가 의도한대로 변경되지 않을수도 있다고?
그렇다. 아래의 코드를 보자
fun main(args: Array<String>) {
val counter = Counter()
val countThread1 = CountWorker(counter)
val countThread2 = CountWorker(counter)
countThread1.start()
countThread2.start()
countThread1.join()
countThread2.join()
println("count: ${counter.count}") // ?
}
class CountWorker(val counter: Counter) : Thread() {
override fun run() {
repeat(10000) {
counter.increment()
}
}
}
class Counter {
var count = 0
fun increment() {
count += 1
}
}
println("count: ${counter.count}")의 출력값은 무엇일까? 20000을 예상하는것이 자연스러울 수 있다. 하지만 결과는 10342, 11548, 11042등으로 매번 다르다. 왜그럴까?
"스레드는 공유변수가 어디서 사용되고 있는 중인지 아닌지 상관하지 않는다."
각 스레드가 increment()를 호출하면 내부적으로는 다음과 같은 작업이 발생한다.
- count 변수에 저장된 값을 읽는다.
- 읽은 count 변수에 1을 더한다.
- count 변수에 2번의 값을 할당한다.
스레드1이 1번 과정을 하고있는 중에 스레드2도 1번 과정을 하게되면 스레드1과 2는 모두 같은 값을 가져와서 1을 더한 후 count 변수에 할당할 것이다. 스레드1이 2번 과정을 수행하고 있는 경우에 스레드2가 1번 과정을 수행하게되는 경우에도 count의 결과값은 의도와 달라지게 된다.
"CPU 멀티코어에서 스레드가 병렬로 실행되는 경우 CPU 캐시에 있는 값이 공유되지 않을 수있다."
count라는 공유변수를 의도대로 increment() 시킬 수 있게 하기 위해서는 어떻게 해야할까?
2. Volatile
공유 변수에 @Volatile 애노테이션을 붙여준다면, 이것은 "이 변수는 메모리에서 불러오고 변경된 값을 메모리에 저장해. + 메모리에서 불러오는 값(Read 값)에 대해서는 최신값임을 보장해줄게." 라는 의미가 된다.
공유 변수는 RAM에 저장되어 있지만, 빈번하게 사용되는 변수의 경우 쓰레드가 자체적으로 자신이 동작되고 있는 CPU Core에 있는 캐시에 저장하기도 한다. 이 경우에는 변수를 읽거나 업데이트하는것이 메모리가 아닌 캐시에서 진행되다, 일정 주기 혹은 텀이 생겼을 때 메모리에 업데이트 된다.
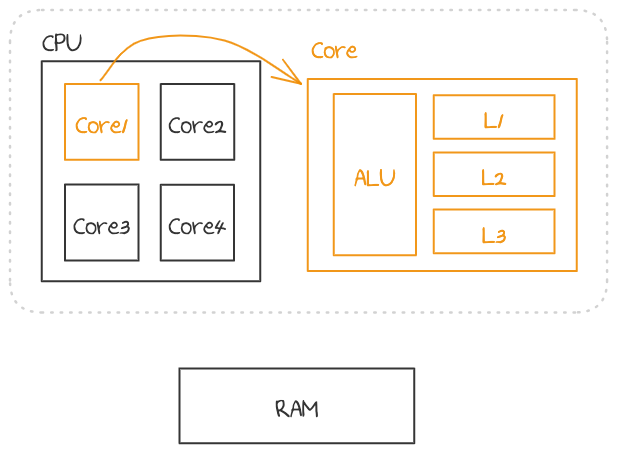
사용하려면 공유 변수에 @Volatile을 붙여주면 된다.
class Counter {
@Volatile var count = 0
fun increment() {
count += 1
}
}
각 스레드가 공유 변수를 캐시에 저장해서 사용하고 있다면, 메모리에 업데이트하고 메모리로 부터 읽는 작업을 게을리해서 문제가 된다면, volatile 키워드로 해결할 수 있다. 하지만 이것은 동시접근을 막는것은 아니기 때문에 두 스레드가 변수에 write operation을 해야한다면, 같은 값을 가져다가 increment() 메서드를 수행할 여지가 남아있다.
참고 포스트
코틀린/자바의 Volatile에 대해서, Charlezz
@Volatile 설명 포스트, chocho_log
3. 상호 배제 (Mutual Exclusion)
하나의 스레드가 공유 변수의 값을 변경하는 동안 다른 스레드가 변수에 접근하지 못하도록 배제시키는 것도 방법이다. 이러한 방식을 Mutex와 Semaphore라고 하는데, Mutex는 Lock(Key)을 이용한 방식, Semaphore는 Signal Count를 이용한 방식이다. 자바와 코틀린에서는 synchronized 키워드로 mutex를 구현할 수 있다. 뮤텍스(Mutex)와 세마포어(Semaphore)의 차이, annual
synchronized는 메서드 정의에 선언하면 synchronized가 해당 클래스의 범위가 된다. (해당 클래스 안에 synchronized 가 된 구간이 모두 공통 관리 범위가 된다.) 메서드 내에 블럭으로 선언하게 되면, 매개변수로 전달되는 객체에 따라 Lock의 범위가 결정된다. (this를 넣는 경우 메서드에 선언하는것과 같이 인스턴스 관리 범위에 들어가지만, 특정 객체를 넣는 경우는 그 객체가 key가 되게 된다.)
synchronized에 대한 여러가지 테스트를 수행한 제리님의 포스트가 있어서 이것을 참고하면 이해에 도움이 될 것이다. 혼동되는 synchronized 동기화 정리, 제리
synchronized를 예제 코드에 적용한다면 아래와 같이 사용할 수 있다.
class Counter {
var count = 0
@Synchronized
fun increment() {
count += 1
}
}
이 방식은 문제를 완전히 해결해준다.
하지만, 한 스레드가 로직을 수행하고 있는 동안 다른 스레드는 수행중인 스레드가 Lock을 해제할 때까지 무한정 기다리게 된다. 다른 스레드는 대기상태에서 다른것을 하지 못하는 것이다. 대기 상태일 때 다른 코루틴을 수행할 수 있게된다면 스레드를 더 효율적으로 사용할 수 있지 않을까?
또 한가지는 대기중인 스레드가 여러개인경우 synchronized의 선정 방식은 임의적이다. 최악의 경우 Thread Starvation이 발생할 수 있다. 이것을 고려해야 한다면, ReentrantLock을 사용해보자.
synchronized VS Reentrant Lock, may_yun
Lock & ReentrantLock, Jaesang Lim
4. 코루틴을 사용한다면, Mutex와 Actor를 고려해보자
4-1. Mutex()
코틀린의 Mutex 객체는 코루틴에 적용되는 mutex이다.
이것은 코루틴이 임계영역에 접근하기위해 대기중인 상태일 때 스레드를 다른 코루틴이 수행될 수 있도록 양보한다. 또 임계영역에 대한 접근 권한을 제어하고 접근이 제한되는 대상은 '코루틴'이다. (synchronized는 스레드였다.) 이것은 하나의 코루틴이 여러 스레드 상에서 수행될 수 있다는 점을 고려한 설계라고 볼 수 있다.
Mutex 객체 사용해 코루틴에 락 걸기, Dev.Cho
코루틴을 사용할 때 ReentrantLock을 사용해 락을 걸면 안되는 이유, Dev.Cho
위의 예제에서는 코루틴을 사용하지 않았기 때문에 간단한 사용 예시를 작성해보도록 하겠다.
class Counter {
private val lock = Mutex()
var count = 0
suspend fun increment() {
lock.withLock {
count += 1
}
}
}
4-2. Actor
actor() 메서드는 코루틴의 채널을 이용해서 내부 로직을 두고 처리하는 객체이다. (코루틴의 채널은 코루틴 사이에서 값을 주고받을 수 있도록 만들어진 Queue라고 생각하면 된다.) 채널은 Queue 방식으로(순서 보장) 메시지를 처리하기 때문에 공유 자원에 대한 동기화 접근을 보장한다.
예제와 비슷하게 사용할 수 있는 코드는 아래와 같다.
import kotlinx.coroutines.*
import kotlinx.coroutines.channels.actor
sealed class CounterMsg
class IncrementMsg : CounterMsg()
class DoneMsg(val response: CompletableDeferred<Int>) : CounterMsg()
fun CoroutineScope.counterActor() = actor<CounterMsg> {
var count = 0
for (msg in channel) {
when (msg) {
is IncrementMsg -> count++
is DoneMsg -> msg.response.complete(count)
}
}
}
fun main() {
runBlocking {
val counter = counterActor()
val job1 = launch {
repeat(10000) {
counter.send(IncrementMsg())
}
}
val job2 = launch {
repeat(10000) {
counter.send(IncrementMsg())
}
}
joinAll(job1, job2)
val response = CompletableDeferred<Int>()
counter.send(DoneMsg(response))
println("counter.count: ${response.await()}")
counter.close()
}
}
5. AtomicType
마지막 방법은 AtomicType을 사용하는 것이다. AtomicType은 말 그대로 '원자성을 보장하는' 타입이다. 원자성을 보장하기 위해 CAS(Compare And Set) 방식을 차용한다. 값을 업데이트 시키기 위해 업데이트 전의 값이 현재 메모리에 있는 값과 같다면 원자성이 유지되었다고 판단하여 업데이트를 진행하지만, 다르다면 다른 스레드가 해당 값을 자신과 동시에 가져가서 먼저 업데이트 시켰다고 판단하여(원자성이 깨졌다.) 업데이트 작업을 재시도한다.
java의 concurrent 패키지 알아보기 (2) Atomic Type 사용하기, 코알라일락
class Counter {
val count = AtomicInteger(0)
fun increment() {
count.incrementAndGet()
}
}
6. 추가 참고 블로그
Thread 3 - 공유자원, 쓰레드 동기화, 김민기 - 스레드 wait(), notify() 부분
그림으로 보는 자바 코드의 메모리 영역(스택 & 힙), 인파